



Самая простая процедура — с помощью компьютера получить таблицу двумерного распределения. Допустим, исследователь хочет проверить гипотезу о влиянии материального уровня жизни на общую удовлетворенность жизнью. Более того, он считает, что на удовлетворенность жизнью влияет не столько реальный уровень материального благополучия, сколько самооценка человеком своего материального статуса.
Допустим, что для измерения самооценки материального статуса в инструментарий был включен вопрос: «К какой группе людей по уровню материальной обеспеченности Вы бы себя отнесли?». Полученные данные показали, что из 1755 опрошенных 4 человека отнесли себя «к высокообеспеченным», 909 — к «людям среднего достатка», 842 — к «малоимущим».
Объявляя этот признак независимой переменной, а ответы на вопрос об удовлетворенности жизнью (с веером ответов, включающим пять вариантов) — зависимой переменной, исследователь может получить два типа двумерных таблиц:
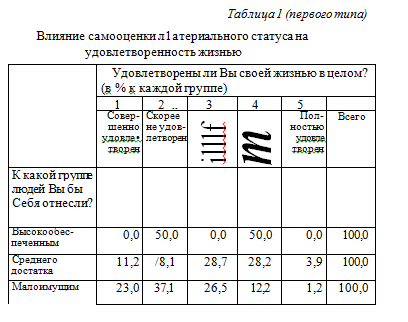
В общем обзоре таблицы просматривается взаимо¬связь между самооценкой материального статуса и удовлетворенностью жизнью. Однако количественное сравнение различных групп по их общей удовлетворенности жизнью при шкале с повышенной степенью точности (в данном случае — 5 градаций) довольно затруднительно.
Обычно, представляя данные по дискретным шкалам, производят укрупнение групп по зависимой переменной (для удобства сравнения между группами по независимой переменной), преобразуя вид таблицы следующим образом.

Преобразованная таким образом таблица позволяет не только «увидеть», что среди лиц «среднего достатка» больше людей, удовлетворенных жизнью, и меньше неудовлетворенных по сравнению с «малоимущими», но и подсчитать, насколько (или во сколько раз) их больше.
Если исследователь, рассматривая рабочую таблицу (в ко-торой указывается не только процент, но и абсолютное значение численности полученных групп), не обратит внимание на то, что к «высокообеспеченным» себя отнесли всего 4 человека (в двумерных распределениях, подготовленных к публикации, абсолютные значения часто не указываются), то он может пытаться найти объяснение тому, что среди «высокообеспеченных» «половина» людей не удовлетворена жизнью, и делать далекоидущие выводы о том, что «не в деньгах счастье», и что повышение уровня жизни выше среднего достатка приводит к повышению доли лиц, не удовлетворенных жизнью и т.д., и т.п.
На самом деле, данные этого опроса не позволяют делать никаких выводов в отношении лиц, относящих себя к высокообеспеченным, поскольку таковых в выборке ока-залось всего 4 человека. Важнейшим правилом при представлении данных многомерных распределений является необходимость учитывать численность полученных групп.
Конечно внимательный исследователь даже на уровне здравого смысла догадается, что группа численностью в четыре человека не может репрезентировать разброс мнений данной категории населения. Возникает вопрос — какой же численности должна быть по¬лученная группа, чтобы по данным ее ответов можно было делать выводы о соответствующей категории населения, сравнивая ее с другими категориями (20, 30, 50, 100 и т.д. человек )?
На этот вопрос нет однозначного ответа, поскольку на репрезентативность полученных данных влияют разные факторы: это и количество характеристик, по которым выборочная группа репрезентирует данную категорию населения, и разброс мнений по исследуемому показателю, и форма распределения т.д.
Но в статистическом анализе существует такой критерий, как значимость различий. Не вдаваясь в математические тонкости формулы расчета значимости различий долей (процентов), отметим лишь необходимость расчета статистической значимости различий в любом случае, когда автор рассуждает о различии в мнениях сравниваемых групп населения, и поясним в самом общем виде, о чем говорит критерий значимости различий долей.
В выборочном социологическом опросе исследователь обычно опрашивает определенную часть населения (выборку), а выводы делает относительно всей исследуемой совокупности (генеральной совокупности); эти же допущения лежат и в основе гpyпп, которые получает автор в процессе анализа (ведь когда он говорит о «высокообеспеченных» или о «малоимущих», он имеет ввиду все население, ограниченное лишь рамками генеральной совокупности).
Предполагается, что выборку автор составил достаточно обоснованно. Но по тем же критериям отбора он может подготовить еще одну выборку. Разумеется, маловероятно, что он получит абсолютно идентичные результаты опроса. Формула расчета значимости различий позволяет учесть доверительную вероятность повторения такого же результата на идентичных выборках: сколько раз будет получен тот же самый результат, если бы исследователь повторил опрос 100 раз на идентичных выборках?
Обычно принято указывать достоверность различий путем расчета коэффициента, показывающего вероятность неправильного решения. Если мы го¬ворим о том, что различия значимы на уровне 5% (0,05), то это означает, что в 95 случаях из 100 мы получим тот же результат.В формулу расчета включаются такие показатели, как численность анализируемой группы, а также доля (процент) лиц давших такой вариант ответа, по которому фиксируется различие. В настоящее время нет необходимости вручную рассчитывать коэффициент значимости различий долей (обычно все программы статистической обработки и анализа позволяют рассчитывать его автоматически).
Задача же исследователя заключается в необходимости установления ко-эффициента значимости различий, прежде разговора о самих различиях. В социологическом анализе принято в качестве верхнего предела рассматривать 5%-ый уровень значимости. Другими словами, при анализе социологических данных, различия в результатах, соответствующий коэффициент для которых, больше значения 5% (0.05), признаются статистически незначимыми.
Следует, конечно, осознавать условность этой границы. Исследователь может представлять данные и с более низким порогом значимости, если считает их достаточно важными. Но в таких случаях он обязательно должен оценить значимость различий процентов, учитывать при общем анализе материала и обязательно указать ее в тексте итого документа.
Но это можно делать только в случаях, когда готовится научный документ Для специалистов. В общем случае, различия, полученные в результате двухмерного анализа, признаются статистически недостоверными, что и требуется подчеркивать, приводя данные в виде двумерных таблиц.
Порядковая шкала, которую автор условно принимает за интервальную, позволяет представить данные двумерного анализа в несколько ином виде (см. таблицу 2). Такой вид данных предпочтительнее, когда шкала ответов имеет достаточно высокую точность: в таком виде легче сравнивать различные группы между собой, так как сравнение можно проводить по одному числу; в таком виде легче увидеть определенные тенденции. Кроме того, анализируемые группы не разбиваются на дополнительные подгруппы в соответствии с ответами по зависимой переменной.

Какие основные требования следует учитывать, представляя данные в таком виде?
Поскольку исследователь данную шкалу определил как интервальную достаточно условно, он должен быть уверен, что полученное распределение по своей форме приближается к нормальному. Мы уже говорили о тех показателях, которые позволяют оценить форму распределения (асимметрия, эксцесс).
Но если даже исследователь их не вычислил, то, по крайней мере, он может сделать самую грубую прикидку — обратить внимание на то, чтобы стандартное отклонение не превышало величину средней. Если стандартное отклонение превышает значение среднего арифметического, то результаты анализа в таком виде (значение средней) представлять нецелесообразно.
Так же, как и в случае сравнения данных в процентах, исследователь должен учитывать уровень значимости различия средних. В формулу расчета входят значения та¬ких параметров, как численность группы, среднее арифметическое и стандартное отклонение.Как следует оформлять таблицу, если она приводится в контексте анализа? Это зависит от целевого назначения текста. Если таблицы приводятся в документах сугубо научного или отчетного характера, то все эти три параметра обязательно должны включаться в соответствующую таблицу, чтобы читатель мог сам пересчитать значимость различий, если его заинтересовали полученные данные.
В научных публикациях автор прежде всего несет ответственность за те основные положения, которые он обосновывает полученными данными. Поэтому в тех случаях, когда различия имеют принципиальный для анализа характер (автор отмечает их в тексте, или сами по себе они представляют социальный интерес, например, сравнивается доверие к различным политическим лидерам и т.п.), исследователь считает значимость различий и указывает результаты расчета в таблице (см. таблицу 2).
Обычно принято одной звездочкой указывать различие, уровень значимости которого 0.05, двумя звездочками — различие, уровень значимости которого 0.01 и тремя звездочками обозначать различие, уровень значимости которого 0.001. В соответствующей части текста обычно принято употреблять слово «различие» («различаются»), если это различие значимо на уровне 0.05, и «существенное различие», если видимое в таблице раз¬личие значимо на уровне 0.01 (и тем более на уровне 0.001).
Если вернуться к данным таблицы 2 и посмотреть полученные результаты — в оДном случае без учета коэффициента значимости различий, а в другом, учитывая этот статистический критерий, то выводы будут различаться. В первом случае, если автор не будет учитывать значимость различий, он может сделать следующий вывод: «Данные позволяют обнаружить тенденцию повышения уровня удовлетворенности жизнью с повышением оценки материального статуса, причем, с переходом на уровень «высокообеспеченных», уровень удовлетворенности жизнью возрастает незначительно».
Но на самом деле, полученные данные не позволяют делать именно такой вывод; как и следовало ожидать, ввиду малочисленности группы «высокообеспеченных», ее отличие по показателю жизненной удовлетворенности статистически не значимо не только по отношению к группе «среднего достатка», но и по отношению к «малоимущим».
Из это не следует, что группа «высокообеспеченных» не отличается от других групп населения по уровню жизненной удовлетворенности; а следует только вывод, что полученные данные не позволяют судить об уровне удовлетворенности жизнью «высокообеспеченных», в том числе и сравнивать этот показатель с другими группами.
Сравнительный анализ малочисленных, с точки зрения возможностей статистических процедур, социальных групп, как уже отмечалось, очень распространенная ошибка в публикациях, посвященных изложению результатов социологических опросов.Поэтому, когда исследователь в результате двумерного анализа обнаруживает, что ответы на тот или иной вопрос анкеты представителей малочисленных групп существенно отличаются от ответов других групп населения, он всегда должен посчитать значимость этих различий.
И если различия статистически незначимы, он на основании данных только своего исследования не может сказать, отражают ли полученные данные реальную картину, или они вызваны нерепрезентативностью выборочной подгруппы по отношению к соответствующей категории населения. Короче, на основании данных опроса, исследователь не может делать никаких выводов в отношении групп, численность которых в выборочной совокупности не позволяет делать статистически обоснованных выводов. Что же должен делать исследователь, если малочисленность группы не позволяет приходить к статистически обоснованным выводам?
Первое, самое простое, решение — убрать из результатов двумерных таблиц, подготавливаемых к широкому обнародованию, данные по группам, численность которых не позволяет делать обоснованных выводов. В противном случае, читатель, видя лишь представленные процентные распределения, будет введен в заблуждение. Конечно, при таком решении, часть информации «к размышлению» теряется. Но это лучше, чем формирование у неискушенного читателя искаженного представления об особенностях общественного сознания.
Второй “путь, который может избрать исследователь, это допустимое укрупнение анализируемых групп. Например, возрастную группу 18-20 лет можно укрупнить (18-25 лет или 18-30 лет и т.д.), увеличивая тем самым ее численность. В приведенной выше таблице 1 группу «высокообеспеченных» можно объединить с группой «среднего достатка», и в сравнительном анализе сопоставлять ответы «малоимущих» с людьми «среднего достатка и выше».
При этом в тексте анализа следует отметить такое укрупнение, уточнив, сколько именно процентов от общей численности выборки составляет присоединенная группа. Разумеется, далеко не все малочисленные группы правомерно объединять с другими категориями.
В некоторых случаях это достаточно очевидно: наверняка, ни один исследователь при сравнительном анализе различных профессиональных категорий не будет объединять в одну группу «военнослужащих», «студентов» и «предпринимателей». Несколько сложнее решать проблему укрупнения групп, полученных по условно порядковым шкалам.
Например, градация ответов на вопрос анкеты, касающийся уровня образования, является случаем условно порядковой шкалы; и исследователь часто затрудняется с решением проблемы, с какой группой можно объединить категорию лиц, имеющих неоконченное высшее образование (эта категория тоже, как правило, в репрезентативных региональных выборках слишком малочисленна для многомерного анализа).
В таких случаях укрупнение групп — самостоятельная творческая проблема, требующая обоснованного решения, которое не следует отдавать на откуп респондентам: произвести укрупнение в анкете (дать не все градации), а там — «пусть респондент сам решает, к какой группе себя отнести». Существует и третий путь решения проблемы возможностей анализа малочисленных групп — подготовка «выпуклой» выборки.






